Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Setting title tag with javascript/jquery
-
Hi there,
I'm looking for some advice. I've recently implemented a few jQuery functions which gets specific content from the page and then sets the title and description.
See working example here.
It seems to work fine but my question I have is whether Google bots can read it and whether it might actually hinder my SEO efforts?
Any advice would be really appreciated!
Peter
-
I don't think your javascript usage is helping you. I am not sure as to why you would nofollow something you sought to improve for SEO.
As to speed, you have more issues than your provider's server. Download Google Insights and run the page speed tool. You will see what I mean.
Best,
-
Robert,
Thanks for the reply!
The main reason for changing the title/description tags with javascript was to make the pages more indexable (and readable on google). Would you say these pages will provide any SEO benefits to the rest of the website? Or would it be better to set a nofollow tag?
I will have a look into speeding up the property pages however it's most likely because the information is being rendered on our software providers server which at the same time is probably handling 1000's of other requests aswell

-
Thanks for the reply!
Unfortunately I cannot do this in PHP as the property details are rendered using XML and I don't have access to the files as it's saved on our software providers server (they have also said they would not know how to implement this) - I also have little to no experience with XML so that's why I thought i'd try javascript.
-
Peter
I agree with Jon,
Also, your page is loading quite slowly when I use Google Pagespeed insights. You might want to run it on the site and just look at what it is suggesting.
Hope this helps you out,
Robert
-
No, Google won't see it - you're meant to make your site accessible to those with JS turned off. Check using GWT 'fetch as Google'.
You could, however, do this with PHP.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

How long does Google takes to re-index title tags?
Hi, We have carried out changes in our website title tags. However, when I search for these pages on Google, I still see the old title tags in the search results. Is there any way to speed this process up? Thanks
Technical SEO | | Kilgray0 -

Same H1 & H2 Tags
Is it bad to have the same H1 & H2 tag on one page? I found a similar question here on the moz forum but it didn't exactly answer my question. And will adding "about" on the H2 help, or should we avoid duplicate tags completely? Here is a link to the page in question (which will repeat throughout this site.) Thanks in advance!
Technical SEO | | Mike.Bean0 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
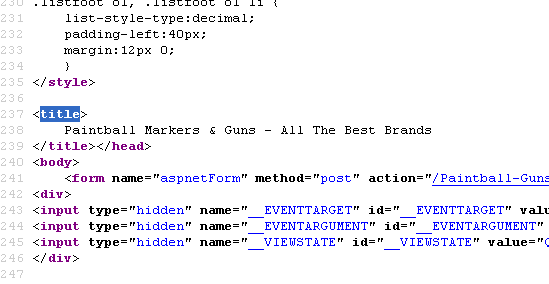 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

<sub>& <sup>tags, any SEO issues?</sup></sub>
Hi - the content on our corporate website is pretty technical, and we include chemical element codes in the text that users would search on (like S02, C02, etc.) A lot of times our engineers request that we list the codes correctly, with a <sub>on the last number. Question - does adding this code into the keyword affect SEO? The code would look like SO<sub>2</sub>.</sub> Thanks.
Technical SEO | | Jenny10 -

Special Characters in Title Tags & Meta Descriptions
Do special characters, such as the "&" symbol or a "," in title tags and meta descriptions negatively affect your ranking in search engines? Any feedback is much appreciated. Thank you!
Technical SEO | | ZAG1 -

Should I include tags in sitemap?
Hello All, I was wondering if you should include tags and categories in your sitemap. In the past on previous blogs I have always left tags and categories out. The reason for this is a good friend of mine who has been doing SEO for a long time and inhouse always told me that this would result in duplicate content. I thought that it would be a great idea to get some input from the SEOmoz community as this obviously has a big affect on your blog and the number of pages indexed. Any help would be great. Thanks, Luke Hutchinson.
Technical SEO | | LukeHutchinson1 -

Home Page .index.htm and .com Duplicate Page Content/Title
I have been whittling away at the duplicate content on my clients' sites, thanks to SEOmoz's pro report, and have been getting push back from the account manager at register.com (the site was built here and the owner doesn't want to move it). He says these are the exact same page and he can't access one to redirect to the other. Any suggestions? The SEOmoz report says there is duplicate content on both these urls: Durango Mountain Biking | Durango Mountain Resort - Cascade Village http://www.cascadevillagehotel.com/index.htm Durango Mountain Biking | Durango Mountain Resort - Cascade Village http://www.cascadevillagehotel.com/ Your help is greatly appreciated! Sheryl
Technical SEO | | TOMMarketingLtd.0 -

Why "title missing or empty" when title tag exists?
Greetings! On Dec 1, 2011 in a SEOMoz campaign, two crawl metrics shot up from zero (Nov 17, Nov 24). "Title missing or empty" was 9,676. "Duplicate page content" was 9,678. Whoa! Content at site has not changed. I checked a sample of web pages and each seems to have a proper TITLE tag. Page content differs as well -- albeit we list electronic part numbers of hard-to-find parts, which look similar. I found a similar post http://www.seomoz.org/q/why-crawl-error-title-missing-or-empty-when-there-is-already-title-and-meta-desciption-in-place . In answer, Sha ran Screaming Frog crawler. I ran Frog crawler on a few hundred pages. Titles were found and hash codes were unique. Hmmm. Site with errors is http://electronics1.usbid.com Small sample of pages with errors: electronics1.usbid.com/catalog_10.html
Technical SEO | | groovykarma
electronics1.usbid.com/catalog_100.html
electronics1.usbid.com/catalog_1000.html I've tried to reproduce errors yet I cannot. What am I missing please? Thanks kindly, Loren0