Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Should I "no-index" two exact pages on Google results?
-
Hello everyone,
I recently started a new wordpress website and created a static homepage.
I noticed that on Google search results, there are two different URLs landing on same content page.
I've attached an image to explain what I saw.
Should I "no-index" the page url?
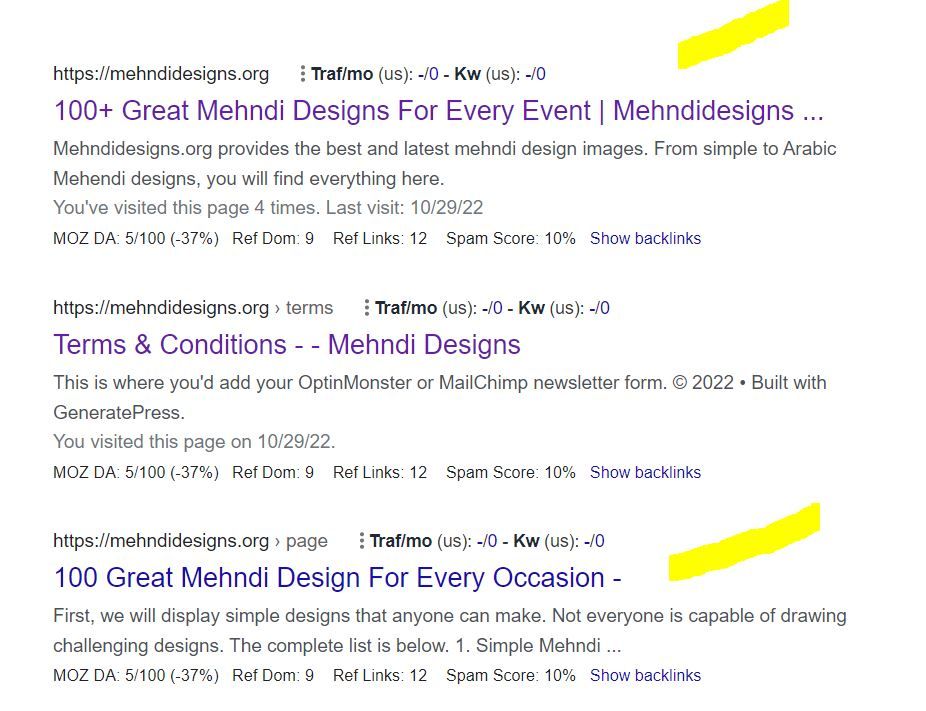
In this picture, the first result is the homepage and I try to rank for that page. The last result is landing on same content with different URL.
So, should I no-index last result as shown in image?
-
In any SEO plugin, you can go to edit the secondary article and in canonical URL you put the link to the home page.
-
@amanda5964 You can use canonical meta tag to tell google that those are the exact same pages. Google will index one of them which google choose best for the SERP.
-
Hi @amanda5964 actually could I ask if there is a reason for having these identical pages? You might want to consider simply combining the pages - i.e. deleting your sub page and redirecting to home if the content is identical.
-
I would not no-index. Typically it is more effective to use a canonical link from the secondary content to the main page you want the traffic directed to.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Who is correct - please help!
I have a website with a lot of product pages - often thousands of pages. As each of these pages is for a specific lease car they are often only fractionally different from other pages. The urls are too long, the H1 is often too long and the Title is often too long for "SEO best practice". And they do create duplication issues according to MOZ. Some people tell me to change them to noindex/nofollow whilst others tell me to leave them as they are as best not to hide from google crawler. Any advice will be gratefully received. Thanks for listening.
Technical SEO | | jlhitch0 -

Good to use disallow or noindex for these?
Hello everyone, I am reaching out to seek your expert advice on a few technical SEO aspects related to my website. I highly value your expertise in this field and would greatly appreciate your insights.
Technical SEO | | williamhuynh
Below are the specific areas I would like to discuss: a. Double and Triple filter pages: I have identified certain URLs on my website that have a canonical tag pointing to the main /quick-ship page. These URLs are as follows: https://www.interiorsecrets.com.au/collections/lounge-chairs/quick-ship+black
https://www.interiorsecrets.com.au/collections/lounge-chairs/quick-ship+black+fabric Considering the need to optimize my crawl budget, I would like to seek your advice on whether it would be advisable to disallow or noindex these pages. My understanding is that by disallowing or noindexing these URLs, search engines can avoid wasting resources on crawling and indexing duplicate or filtered content. I would greatly appreciate your guidance on this matter. b. Page URLs with parameters: I have noticed that some of my page URLs include parameters such as ?variant and ?limit. Although these URLs already have canonical tags in place, I would like to understand whether it is still recommended to disallow or noindex them to further conserve crawl budget. My understanding is that by doing so, search engines can prevent the unnecessary expenditure of resources on indexing redundant variations of the same content. I would be grateful for your expert opinion on this matter. Additionally, I would be delighted if you could provide any suggestions regarding internal linking strategies tailored to my website's structure and content. Any insights or recommendations you can offer would be highly valuable to me. Thank you in advance for your time and expertise in addressing these concerns. I genuinely appreciate your assistance. If you require any further information or clarification, please let me know. I look forward to hearing from you. Cheers!0 -

Footer backlink for/to Web Design Agency
I read some old (10+ years) information on whether footer backlinks from the websites that design agencies build are seen as spammy and potentially cause a negative effect. We have over 150 websites that we have built over the last few years, all with sitewide footer backlinks back to our homepage (designed and managed by COMPANY NAME). Semrush flags some of the links as potential spammy links. What are the current thoughts on this type of footer backlink? Are we better to have 1 dofollow backlink and the rest of the website nofollow from each domain?
Link Building | | MultiAdE1 -

How to rank a website in different countries
I have a website which I want to rank in UK, NZ and AU and I want to keep my domain as .com in all the countries. I have specified the lang=en now what needs to be done to rank one website in 3 different English countries without changing the domain extension i.e. .com.au or .com.nz
SEO Tactics | | Ravi_Rana0 -

My WP website got attack by malware & now my website site:www.example.ca shows about 43000 indexed page in google.
Hi All My wordpress website got attack by malware last week. It affected my index page in google badly. my typical site:example.ca shows about 130 indexed pages on google. Now it shows about 43000 indexed pages. I had my server company tech support scan my site and clean the malware yesterday. But it still shows the same number of indexed page on google.
Technical SEO | | ChophelDoes anybody had ever experience such situation and how did you fixed it. Looking for help. Thanks FILE HIT LIST:
{YARA}Spam_PHP_WPVCD_ContentInjection : /home/example/public_html/wp-includes/wp-tmp.php
{YARA}Backdoor_PHP_WPVCD_Deployer : /home/example/public_html/wp-includes/wp-vcd.php
{YARA}Backdoor_PHP_WPVCD_Deployer : /home/example/public_html/wp-content/themes/oceanwp.zip
{YARA}webshell_webshell_cnseay02_1 : /home/example2/public_html/content.php
{YARA}eval_post : /home/example2/public_html/wp-includes/63292236.php
{YARA}webshell_webshell_cnseay02_1 : /home/example3/public_html/content.php
{YARA}eval_post : /home/example4/public_html/wp-admin/28855846.php
{HEX}php.generic.malware.442 : /home/example5/public_html/wp-22.php
{HEX}php.generic.cav7.421 : /home/example5/public_html/SEUN.php
{HEX}php.generic.malware.442 : /home/example5/public_html/Webhook.php0 -

Should search pages be indexed?
Hey guys, I've always believed that search pages should be no-indexed but now I'm wondering if there is an argument to index them? Appreciate any thoughts!
Technical SEO | | RebekahVP0 -

How to check if an individual page is indexed by Google?
So my understanding is that you can use site: [page url without http] to check if a page is indexed by Google, is this 100% reliable though? Just recently Ive worked on a few pages that have not shown up when Ive checked them using site: but they do show up when using info: and also show their cached versions, also the rest of the site and pages above it (the url I was checking was quite deep) are indexed just fine. What does this mean? thank you p.s I do not have WMT or GA access for these sites
Technical SEO | | linklander0 -

Google is Showing Website as "Untitled"
My freelance designer made some changes to my website and all of a sudden my homepage was showing the title I have in Dmoz. We thought maybe the NOODP tag was not correct, so we edited that a little and now the site is showing as "Untitled". The website is http://www.chemistrystore.com/. Of course he didn't save an old copy that we can revert to. That is a practice that will end. I have no idea why the title and description that we have set for the homepage is not showing in google when it previously was. Another weird thing that I noticed is that when I do ( site:chemistrystore.com ) in Google I get the https version of the site showing with the correct title and description. When I do ( site:www.chemistrystore.com ) in Google I don't have the hompage showing up from what I can tell, but there are 4,000+ pages to the site. My guess is that if it is showing up, it is showing up as "Untitled". My question is.... How can we get Google to start displaying the proper title and description again?
Technical SEO | | slangdon0